


Structure learning benchmarks in Scutari, Journal of Machine Learning Research (2016)
This is a short HOWTO describing the simulation setup used in “An Empirical-Bayes
Score for Discrete Bayesian Networks” by Scutari (2016, PGM Proceedings). We compared
different networks scores used in structure learning over a set of 10 reference networks
from the Bayesian network repository and a range of sample sizes.
The simulation is orchestrated from the makefile below.
NETWORKS := $(sort $(patsubst %.rda,%.rda.done,$(wildcard networks/*.rda))) learning: $(NETWORKS) networks/%.rda.done: networks/%.rda mkdir -p results Rscript --vanilla learning.R $< comparing: learning mkdir -p summaries Rscript --vanilla comparing.R tabulating: comparing Rscript --vanilla tabulating.R figures: comparing mkdir -p figures Rscript --vanilla plotting.R clean: rm -rf summaries results figures networks/*.done .PHONY: learning clean comparing tabulating figures
The tasks performed by the various targets are the following:
learning: takes all the networks saved in thenetworksdirectory, and iterates over them running thenetworks/%.rda.donetarget for each of them;networks/%.rda.done: calls thelearning.RR script (which performs structure learning and saves the results in theresultsdirectory) on the reference network saved in thenetworks/%.rda;comparing: computes the metrics of interest from the networks inresultsand saves them in thesummariesdirectory;tabulating: computes the averages of the metrics of interest for each reference network and sample size;figures: produces boxplots comparing different scores for each network, using the metrics saved in thesummariesdirectory;clean: removes all the files produced by the other targets.
Note that calling make executes only the learning target; other
targets are not executed automatically and have to be run manually by calling
make comparing, make tabulating or make figures. The
dependencies specified in the makefile ensure that previous targets are executed
and in the correct order.
Learning the network structures
The R script learning.R is reported below, with comments.
First, we load bnlearn (to perform structure learning) and
parallel (to do that in parallel and speed up the simulation). Then we
read the name of the file containing the reference network (rda.file), we
produce a label for the network from it (rda.label), and we set three key
parameters of the simulation:
np.ratios, which controls the sizes of the samples generated from the reference networks. The sizes are expressed as number of samples / number of parameters (n/p), relative to the complexity of the network, to obtain results that are comparable across (very different) networks.runs, the number of samples that are generated for each combination of reference network and sample size.slaves, the number of slave processes used by parallel. The largest number that makes sense isruns, which allows all the runs to be executed in parallel.
> library(bnlearn) > library(parallel) > > rda.file = commandArgs(trailingOnly = TRUE) > rda.label = toupper(gsub("networks/(.+)\\.rda$", "\\1", rda.file)) > > np.ratios = c(0.1, 0.2, 0.5, 1, 2, 5) > > runs = 20 > slaves = 20
Then we define the benchmark() function, which runs the simulations
for all the network scores and all the sample sizes for a single network. This
function is structured as follows:
- generates a training sample of the appropriate size using
rbn(); - learns various network structures calling
hc()with different network scores and/or tuning parameters; - returns a list containing both the training sample (
dtrain) and the learned structures (dag.bic,dag.bde1, etc.).
Applying all the network scores to the same training set(s) reduces simulation variability when computing differences between metrics of interest. Testing for significant differences between paired values provides more power that testing independent values; and this in turn makes it possible to perform a limited number of runs and still obtain statistically significant results.
Furthermore, returning the generated sample along with the learned networks makes it
possible to learn their parameters with bn.fit() and to easily add more
scores at a later time.
> benchmark = function(bn, n) { + # generate the training set. + dtrain = rbn(bn, n) + # use BIC. + dag.bic = hc(dtrain, score = "bic") + # use BDeu with iss = 1, 10. + dag.bde1 = hc(dtrain, score = "bde", iss = 1) + dag.bde10 = hc(dtrain, score = "bde", iss = 10) + # use BDes with iss = 1, 10. + dag.bds1 = hc(dtrain, score = "bds", iss = 1) + dag.bds10 = hc(dtrain, score = "bds", iss = 10) + # set a really uniform marginal prior 0.25/0.5/0.25. + dag.bde.cs1 = hc(dtrain, score = "bde", prior = "marginal", iss = 1) + dag.bde.cs10 = hc(dtrain, score = "bde", prior = "marginal", iss = 10) + # combine BDs with the really uniform marginal prior. + dag.bds.cs1 = hc(dtrain, score = "bds", prior = "marginal", iss = 1) + dag.bds.cs10 = hc(dtrain, score = "bds", prior = "marginal", iss = 10) + # use the optimal alpha estimator from Harald Steck. + dag.alpha.star = dag.bic + for (i in 1:3) { + alpha.star = alpha.star(dag.alpha.star, dtrain) + dag.alpha.star = hc(dtrain, score = "bde", iss = alpha.star) + }#FOR + return(list(dag.bic = dag.bic, dag.bde1 = dag.bde1, dag.bde10 = dag.bde10, + dag.bds1 = dag.bds1, dag.bds10 = dag.bds10, dag.bde.cs1 = dag.bde.cs1, + dag.bde.cs10 = dag.bde.cs10, dag.bds.cs1 = dag.bde.cs1, + dag.bds.cs10 = dag.bds.cs10, dag.alpha.star = dag.alpha.star, + dtrain = dtrain)) + }#BENCHMARK
Finally, we perform the simulations. After loading the reference network and
computing the absolute sizes (n) of the samples that will be generated
by benchmark(), we iterate over said sample sizes and:
- initialize the parallel cluster (
makeCluster()); - initialize random number generation in the slaves (
clusterSetRNGStream()); - export
benchmark()and load bnlearn in the slaves; - run
benchmark()in the slaves viaparLapply()and get the simulation results back in thesim; - save the value of
np.ratiosandrda.labelas attributes ofsim; - save
simas a RDA file in theresultsdirectory.
Note that we stop and start a new cluster in each iteration to make sure memory is used efficiently and to avoid leaks caused by slow reclaims by the R garbage collection; and to make sure the slave status is “clean” at each new run.
> # load the golden standard network. > load(rda.file) > # choose the sample sizes as multiples of the number of parameters. > n = ceiling(np.ratios * nparams(bn)) > > # fork the slaves inside the cycle, so that they are killed at each iteration > # and we avoid some of R's memory leaks. > for (j in seq_along(n)) { + # start the cluster and set the random number generators in the slaves. + cl = makeCluster(slaves) + clusterSetRNGStream(cl, 42) + # load bnlearn and export the function doing the learning. + invisible(clusterEvalQ(cl, library(bnlearn))) + invisible(clusterExport(cl, "benchmark")) + sim = parLapply(cl, seq(runs), function(x, bn, n) { + benchmark(bn, n) + }, bn = bn, n = n[j]) + # save additional information as attributes. + attr(sim, "np.ratio") = np.ratios[j] + attr(sim, "network") = rda.label + # save the runs in a separate file for each network + sample size + # combination. + save(sim, file = paste0("results/", rda.label, + "[", np.ratios[j], "].rda")) + stopCluster(cl) + }#FOR
Last but not least, we create the .done file that is used by
make to tell the simulation has been completed.
> # save a placeholder for the makefile. > file.create(paste0(rda.file, ".done"))
Computing the metrics of interest to compare different network scores
The R script comparing.R is reported below, with comments.
First, we load bnlearn and save the list of RDA files generated by the
learning.R script in benchmarks.
> library(bnlearn) > > # compute the SHD distance from the reference network. > benchmarks = list.files("results", pattern = "*.rda$", full.names = TRUE)
Then we create an empty data frame to hold the values of the metric we will use to evaluate the networks learned with the different network scores; we will iteratively append batches of values to this data frame in the loop below.
> metrics = data.frame( + LABEL = character(0), + NP = numeric(0), + SHD.BIC = numeric(0), + SHD.BDE1 = numeric(0), + SHD.BDE10 = numeric(0), + SHD.BDS1 = numeric(0), + SHD.BDS10 = numeric(0), + SHD.STAR = numeric(0), + SHD.BDECS1 = numeric(0), + SHD.BDECS10 = numeric(0), + SHD.BDSCS1 = numeric(0), + SHD.BDSCS10 = numeric(0) + )
Finally, we set our metric to be the SHD distance between the learned and the true DAG from the reference network, and we compute it for each network learned from each training data set by:
- loading each of the files in
benchmarks; - getting the true DAG from the reference network with
bn.net(); - wrap a convenience function called
metric()aroundshd(); - call
metric()on each of the 20runsusingsapply(), separately for each network score; - save the results from
metric()in a data frame calledcurrentwith the same structure as themetricsdata frame we created above; - append
currenttometrics.
> for (b in benchmarks) { + # load the file with the network structures. + load(b) + runs = length(sim) + # load the golden standard network. + label = attr(sim, "network") + load(paste0("networks/", tolower(label), ".rda")) + true.dag = bn.net(bn) + metric = function(x, label) shd(x[[label]], true.dag) + current = data.frame( + LABEL = rep(label, runs), + NP = rep(attr(sim, "np.ratio"), runs), + SHD.BIC = sapply(sim, metric, label = "dag.bic"), + SHD.BDE1 = sapply(sim, metric, label = "dag.bde1"), + SHD.BDE10 = sapply(sim, metric, label = "dag.bde10"), + SHD.BDS1 = sapply(sim, metric, label = "dag.bds1"), + SHD.BDS10 = sapply(sim, metric, label = "dag.bds10"), + SHD.STAR = sapply(sim, metric, label = "dag.alpha.star"), + SHD.BDECS1 = sapply(sim, metric, label = "dag.bde.cs1"), + SHD.BDECS10 = sapply(sim, metric, label = "dag.bde.cs10"), + SHD.BDSCS1 = sapply(sim, metric, label = "dag.bds.cs1"), + SHD.BDSCS10 = sapply(sim, metric, label = "dag.bds.cs10") + ) + metrics = rbind(metrics, current) + }#FOR
Finally, we save the metrics, which now contains the SHD distances for all
the networks that were learned in learning.R, in a files called
shd.comparison.txt.xz in the summaries directory.
> xzfd = xzfile("summaries/shd.comparison.txt.xz", open = "w") > write.table(metrics, file = xzfd, row.names = FALSE) > close(xzfd)
In the rest of comparing.R we repeat the process above to compute the number
of arcs and the predictive log-likelihood for all the networks that were learned in
learning.R, and we save them in two files named arcs.comparison.txt.xz
and test.loglik.comparison.txt.xz.
> # compute the number of arcs. > metrics = data.frame( + LABEL = character(0), + NP = numeric(0), + GOLDEN = numeric(0), + ARCS.BIC = numeric(0), + ARCS.BDE1 = numeric(0), + ARCS.BDE10 = numeric(0), + ARCS.BDS1 = numeric(0), + ARCS.BDS10 = numeric(0), + ARCS.STAR = numeric(0), + ARCS.BDECS1 = numeric(0), + ARCS.BDECS10 = numeric(0), + ARCS.BDSCS1 = numeric(0), + ARCS.BDSCS10 = numeric(0) + ) > > for (b in benchmarks) { + # load the file with the network structures. + load(b) + runs = length(sim) + # load the golden standard network. + label = attr(sim, "network") + load(paste0("networks/", tolower(label), ".rda")) + true.dag = bn.net(bn) + metric = function(x, label) narcs(x[[label]]) + current = data.frame( + LABEL = rep(label, runs), + NP = rep(attr(sim, "np.ratio"), runs), + GOLDEN = narcs(true.dag), + ARCS.BIC = sapply(sim, metric, label = "dag.bic"), + ARCS.BDE1 = sapply(sim, metric, label = "dag.bde1"), + ARCS.BDE10 = sapply(sim, metric, label = "dag.bde10"), + ARCS.BDS1 = sapply(sim, metric, label = "dag.bds1"), + ARCS.BDS10 = sapply(sim, matric, label = "dag.bds10"), + ARCS.STAR = sapply(sim, metric, label = "dag.alpha.star"), + ARCS.BDECS1 = sapply(sim, metric, label = "dag.bde.cs1"), + ARCS.BDECS10 = sapply(sim, matric, label = "dag.bde.cs10"), + ARCS.BDSCS1 = sapply(sim, metric, label = "dag.bds.cs1"), + ARCS.BDSCS10 = sapply(sim, matric, label = "dag.bds.cs10") + ) + metrics = rbind(metrics, current) + }#FOR > > xzfd = xzfile("summaries/arcs.comparison.txt.xz", open = "w") > write.table(metrics, file = xzfd, row.names = FALSE) > close(xzfd)
> # compute the log-likelihood loss for a test set. > metrics = data.frame( + LABEL = character(0), + NP = numeric(0), + LOGLIK.BIC = numeric(0), + LOGLIK.BDE1 = numeric(0), + LOGLIK.BDE10 = numeric(0), + LOGLIK.BDS1 = numeric(0), + LOGLIK.BDS10 = numeric(0), + LOGLIK.STAR = numeric(0), + LOGLIK.BDECS1 = numeric(0), + LOGLIK.BDECS10 = numeric(0), + LOGLIK.BDSCS1 = numeric(0), + LOGLIK.BDSCS10 = numeric(0) + ) > > for (b in benchmarks) { + # load the file with the network structures. + load(b) + runs = length(sim) + # load the golden standard network. + label = attr(sim, "network") + load(paste0("networks/", tolower(label), ".rda")) + true.dag = bn.net(bn) + dtest = rbn(bn, 10000) + metric = function(x, label) { + logLik(bn.fit(x[[label]], x$dtrain, method = "bayes", iss = 1), dtest) + }#METRIC + current = data.frame( + LABEL = rep(label, runs), + NP = rep(attr(sim, "np.ratio"), runs), + LOGLIK.BIC = sapply(sim, metric, label = "dag.bic"), + LOGLIK.BDE1 = sapply(sim, metric, label = "dag.bde1"), + LOGLIK.BDE10 = sapply(sim, metric, label= "dag.bde10"), + LOGLIK.BDS1 = sapply(sim, metric, label = "dag.bds1"), + LOGLIK.BDS10 = sapply(sim, metric, label = "dag.bds10"), + LOGLIK.STAR = sapply(sim, metric, label = "dag.alpha.star"), + LOGLIK.BDECS1 = sapply(sim, metric, label = "dag.bde.cs1"), + LOGLIK.BDECS10 = sapply(sim, metric, label = "dag.bde.cs10"), + LOGLIK.BDSCS1 = sapply(sim, metric, label = "dag.bds.cs1"), + LOGLIK.BDSCS10 = sapply(sim, metric, label = "dag.bds.cs10") + ) + metrics = rbind(metrics, current) + }#FOR > > xzfd = xzfile("summaries/test.loglik.comparison.txt.xz", open = "w") > write.table(metrics, file = xzfd, row.names = FALSE) > close(xzfd)
Computing the averaged metrics for each network and sample size
The R script tabulating.R is reported below, with comments.
The purpose of this R script is to load each of the files created by
comparing and to compute the average of each metric for each reference
network and for each sample size. In order to do that, we first load the doBy
and bnlearn packages and we read shd.comparison.txt.xz,
arcs.comparison.txt.xz and test.loglik.comparison.txt.xz.
> library(doBy) > library(bnlearn) > > xzfd = xzfile("summaries/shd.comparison.txt.xz", open = "r") > metrics.shd = read.table(xzfd, header = TRUE) > close(xzfd) > > xzfd = xzfile("summaries/arcs.comparison.txt.xz", open = "r") > metrics.narcs = read.table(xzfd, header = TRUE) > close(xzfd) > > xzfd = xzfile("summaries/test.loglik.comparison.txt.xz", open = "r") > metrics.loglik = read.table(xzfd, header = TRUE) > close(xzfd) > > options(width = 120)
Then we use the summaryBy function from doBy to
compute the average SHD, the average number of arcs (rescaled by the number of
arcs in the reference network) and the average predictive log-likelihood (scaled
by -10000). The averaging is performed for each combination of LABEL,
the label of the reference network, and NP, the ratio between number
of samples in the training data set and the number of parameters in the reference
network.
> # tabulate the SHD. > shd.mean = summaryBy(. ~ LABEL + NP, data = metrics.shd, keep.names = TRUE) > shd.mean > > # tabulate the number of arcs. > narcs.mean = summaryBy(. ~ LABEL + NP, + data = metrics.narcs, keep.names = TRUE) > > for (net in levels(narcs.mean$LABEL)) { + load(paste("networks/", tolower(net), ".rda", sep = "")) + narcs.mean[narcs.mean$LABEL == net, -(1:2)] = + narcs.mean[narcs.mean$LABEL == net, -(1:2)] / narcs(bn) + }#FOR > > narcs.mean > > # tabulate the predictive log-likelihood. > loglik.mean = summaryBy(. ~ LABEL + NP, + data = metrics.loglik, keep.names = TRUE, + FUN = function(x) - mean(x) / 100000) > loglik.mean
Plotting the metrics of interest, for visual inspection
The first part of the R script plotting.R is reported below, with comments.
The script defines a function side.by.side() that uses the lattice
package and its boxplot function bwplot() to produce, for each reference network in
turn, a grouped boxplot that can be used to compare the network scores at different sample sizes
(on the relative scale given by NP, the ratio between the sample size and the
number of parameters in the reference network).
> library(lattice) > > side.by.side = function(data, network, measure, score.subset) { + # keep only the relevant network. + data = data[data$LABEL == network, ] + # reshape in tall format for use in lattice. + data = reshape(data, varying = grep(measure, names(data)), direction = "long", + timevar = "SCORE") + data$NP = as.factor(data$NP) + data$SCORE = factor(data$SCORE, levels = c("BIC", "STAR", "BDE1", "BDS1", + "BDECS1", "BDSCS1", "BDE10", "BDS10", "BDECS10", "BDSCS10")) + nscores = nlevels(data$SCORE) + fill = c("lightsteelblue", "ivory", + apply(expand.grid(c("lightpink", "darkolivegreen", "aquamarine", "coral"), 1:2), 1, + paste, collapse = " ")) + bwplot(get(measure) ~ NP, groups = SCORE, data = data, + pch = 19, box.width = 1/(nscores + 1), fill = fill, + main = toupper(network), xlab = "n/p", ylab = measure, + panel = panel.superpose, + panel.groups = function(x, y, ..., group.number) { + panel.bwplot(x + (group.number-nscores/1.8)/(nscores + 1), y, ...) + panel.abline(v = seq(nscores - 2) + 0.5, lty = 2, col = "lightgrey") + if ("GOLDEN" %in% names(data)) + panel.abline(h = data[1, "GOLDEN"], lwd = 1.5) + }, + par.settings = list(box.umbrella = list(lty = 1, col = "black"), + box.rectangle = list(col = "black"), plot.symbol = list(col = "black"))) + }#SIDE.BY.SIDE
After loading the reference networks from the networks directory, and
the files with the metrics from the summaries directory, we iterate over
the reference networks and generate the plots for each metric.
> rda.files = list.files("networks", pattern = "*.rda$", full.names = TRUE) > rda.labels = toupper(gsub("networks/(.+)\\.rda$", "\\1", rda.files)) > > xzfd = xzfile("summaries/arcs.comparison.txt.xz", open = "r") > metrics.arcs = read.table(xzfd, header = TRUE) > close(xzfd) > > xzfd = xzfile("summaries/shd.comparison.txt.xz", open = "r") > metrics.shd = read.table(xzfd, header = TRUE) > close(xzfd) > > xzfd = xzfile("summaries/test.loglik.comparison.txt.xz", open = "r") > metrics.loglik = read.table(xzfd, header = TRUE) > close(xzfd) > > for (i in seq_along(rda.labels)) { + pdf(paste0("figures/", tolower(rda.labels[i]), ".shd.comparison.pdf"), + width = 18, height = 12, paper = "special", useDingbats = FALSE) + print(side.by.side(metrics.shd, rda.labels[i], measure = "SHD")) + dev.off() + pdf(paste0("figures/", tolower(rda.labels[i]), ".arcs.comparison.pdf"), + width = 18, height = 12, paper = "special", useDingbats = FALSE) + print(side.by.side(metrics.arcs, rda.labels[i], measure = "ARCS")) + dev.off() + pdf(paste0("figures/", tolower(rda.labels[i]), ".test.loglik.pdf"), + width = 18, height = 12, paper = "special", useDingbats = FALSE) + print(side.by.side(metrics.loglik, rda.labels[i], measure = "LOGLIK")) + dev.off() + }#FOR
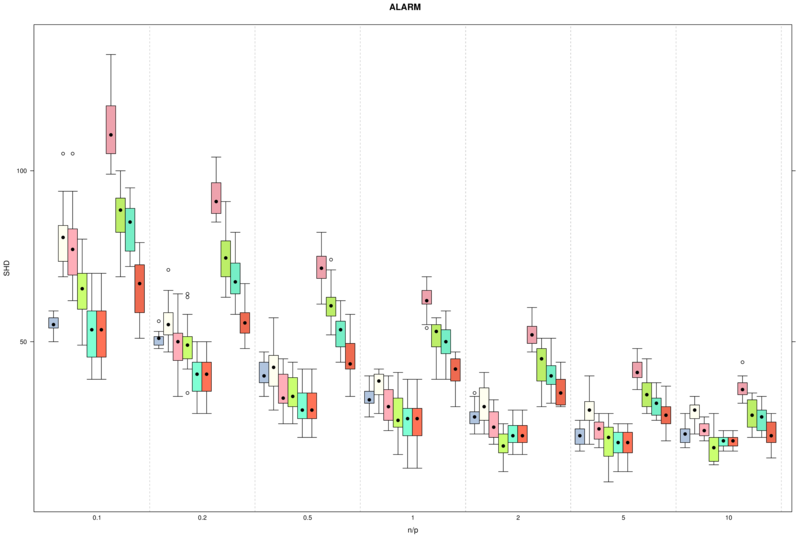
An example of the figures generated by side.by.side() is the
summary figure for ALARM and the SHD distance from the reference network, which
looks as follows.
Plotting the metrics of interest, for slides presentations
The second part of the R script plotting.R is reported below, with comments.
The figures generated by side.by.side() are not suitable for slides
presentations, because of their dimensions and because of the lack of a legend exaplaining
what boxplot corresponds to which score. The function slides.figures() below
creates boxplots that do not have these shortcomings.
> slides.figures = function(data, network, measure, score.subset) { + # keep only the relevant network. + data = data[data$LABEL == network, ] + # reshape in tall format for use in lattice. + data = reshape(data, varying = grep(measure, names(data)), direction = "long", + timevar = "SCORE") + data = data[data$NP < 10, ] + data$NP = as.factor(data$NP) + data$SCORE = factor(data$SCORE, levels = c("BIC", "STAR", "BDE1", "BDS1", + "BDECS1", "BDSCS1", "BDE10", "BDS10", "BDECS10", "BDSCS10")) + data = data[data$SCORE %in% c("BIC", "BDE1", "BDS1", "BDECS1", "BDSCS1", "BDE10", "BDS10", "BDECS10", "BDSCS10"), ] + data$SCORE = droplevels(data$SCORE) + nscores = nlevels(data$SCORE) + fill = c("lightsteelblue", + apply(expand.grid(c("lightpink", "darkolivegreen", "aquamarine", "coral"), c(1, 3)), 1, + paste, collapse = "")) + if (measure != "LOGLIK") + corner = c(0.95, 0.98) + else + corner = c(0.95, 0.05) + bwplot(get(measure) ~ NP, groups = SCORE, data = data, + pch = 19, box.width = 1/(nscores + 1), fill = fill, + main = "", xlab = "", ylab = "", + auto.key = list(points = FALSE, rectangles = TRUE, corner = corner, + text = c("BIC", + expression(U+BDeu * ", " * alpha==1), + expression(U+BDs * ", " * alpha==1), + expression(MU+BDeu * ", " * alpha==1), + expression(MU+BDs * ", " * alpha==1), + expression(U+BDeu * ", " * alpha==10), + expression(U+BDs * ", " * alpha==10), + expression(MU+BDeu * ", " * alpha==10), + expression(MU+BDs * ", " * alpha==10))), + panel = panel.superpose, + panel.groups = function(x, y, ..., group.number) { + panel.bwplot(x + (group.number-nscores/1.8)/(nscores + 1), y, ...) + panel.abline(v = seq(nscores - 2) + 0.5, lty = 2, col = "lightgrey") + if ("GOLDEN" %in% names(data)) + panel.abline(h = data[1, "GOLDEN"], lwd = 1.5, lty = 2, col = "grey") + }, + par.settings = list(box.umbrella = list(lty = 1, col = "black"), + box.rectangle = list(col = "black"), plot.symbol = list(col = "black"), + superpose.polygon = list(col = fill))) + }#SLIDES.FIGURES
> for (i in seq_along(rda.labels)) { + pdf(paste0("figures/slides.", tolower(rda.labels[i]), ".shd.comparison.pdf"), + width = 7, height = 5, paper = "special", useDingbats = FALSE) + print(slides.figures(metrics.shd, rda.labels[i], measure = "SHD")) + dev.off() + pdf(paste0("figures/slides.", tolower(rda.labels[i]), ".arcs.comparison.pdf"), + width = 7, height = 5, paper = "special", useDingbats = FALSE) + print(slides.figures(metrics.arcs, rda.labels[i], measure = "ARCS")) + dev.off() + pdf(paste0("figures/slides.", tolower(rda.labels[i]), ".test.loglik.pdf"), + width = 7, height = 5, paper = "special", useDingbats = FALSE) + print(slides.figures(metrics.loglik, rda.labels[i], measure = "LOGLIK")) + dev.off() + }#FOR
Again, here is the network scores comparison for the ALARM network in terms of SHD.

Mon Jul 10 12:03:16 2017 with bnlearn
4.2
and R version 3.0.2 (2013-09-25).

