


No software is ever finished...
Once upon a time, when the dinosaurs still roamed the earth, I was an M.Sc. student in Statistics and Computer Science at Università di Padova. Having reached the last year of my degree, I had to sit down and decide which supervisor to approach for my dissertation. As anybody who has been a graduate student knows, this can be a difficult choice for a number of reasons. First of all, choosing what topic to work on is difficult because it forces you to decide what topics are “interesting” without being completely familiar with them (if at all). This also forces you to define what “interesting” means to you, and how “interesting” is related to “fashionable” and “transferable” for either academia or industry (or both). Then there is the problem that, in any given department, there are only so many people available to supervise M.Sc. students; and that in turn means that choosing a topic in practice means choosing your (only possible) supervisor. Which makes you consider whether you can work with that person effectively at both a personal and professional level.
Fortunately, I knew whom I wanted to work with, which solved the second problem for me. A few months earlier, I had taken a course in Bayesian statistics with Adriana Brogini, which I found extremely interesting. I had set the examination at the end of the course, which was a classic Italian-style oral examination; since only few students showed up in that session, Adriana had ample time and had grilled me for 45 minutes straight on every last bit of material from the lectures. While that had been a test of endurance I will never forget (thanks to 30°+ Italian summer temperatures), it had left me with a strong confidence in my grasp of the topic and an undying respect for Adriana, because that had actually been fun! So, when I approached her to enquire about dissertation topics, I was ready to undertake whatever project she would put on the table. Her choice was Bayesian networks; and so the trajectory of my research was set.
The topic suited (and suits me well), for a number of reasons. Research on Bayesian networks spans both Statistics and Computer Science, which made it a good choice to match my joint-honours degree. It has strong ties with multivariate statistics, Bayesian statistics, probability, and information theory (helped by an amazing course from Lorenzo Finesso). And Bayesian networks, in either their probabilistic or causal interpretation, are used in many applied fields as a tool for decision support and modelling complex phenomena. Because of this breadth of connections I have been able to branch my research in many directions and to tackle several different aspects of statistics and machine learning, which makes academic life varied interesting, lets me meet interesting people from different disciplines, and prevents me from falling into the trap of ending up “knowing everything about nothing”.
In that respect, I really liked my M.Sc. dissertation work, and what followed during my tenure as a Ph.D. student in Statistics. I had a good excuse to hole up in the library and study more linear algebra (with helpful pointers from Luigi Salce), discrete probability, multivariate statistics, and information theory, spending days just wandering through tons of the books, shelf after shelf of them. And I had an excuse to spend much time coding and implementing the stuff I was studying; back then, as now, I find that computer code is a clearer way of formalising and thinking about most problems than mathematical notation. And that was what stumped me: why almost nobody was doing the same? At that time most papers did not come with a draft implementation of the techniques they introduced, which meant that I had to implement everything myself from very terse pseudocode listings and high-level descriptions. (As anybody who has some experience in programming knows very well, even detailed specifications leave out key details and corner cases. This is true for journal papers, and doubly so for conference papers.) And so the bnlearn package was born, 10 years ago on June 12, 2007.
The package has changed much over the course of 10 years. I have implemented many structure learning algorithms, parameter learning, approximate inference; discrete, Gaussian and conditional Gaussian Bayesian networks; basic and advanced plotting facilities based on lattice and Rgraphviz; import and export to various file formats, with an updated edition of the Bayesian network repository. In part, this has been to support my own research: I need a modular simulation suite with fast and flexible implementations of a wide range of methods. But a key factor has definitely been queries from people in industry and academia looking for software to analyse their data. For those people, bnlearn has fulfilled the promise of interpretable graphical models and flexible, causal inference outlined in Judea's Pearl “Probabilistic Reasoning in Intelligent systems” and “Causality” books, by providing a toolbox integrated into the R statistical environment. And in return, people using bnlearn have provided me an endless stream of bug reports, feature requests, and most importantly discussions and collaborations on applied problems. It is not a stretch to say that a sizeable part of my work as a programmer and as a researcher originates from enquiries I receive about analysing data with bnlearn, in a virtuous cycle of tackling more and more analysis workflows. This has led, much to my surprise, to its growing popularity: it was the 20th most cited R package in the Journal of Statistical Software according to Google Metrics in 2015 (when the reference paper dropped out due to its age); and it reached 500 citation in early 2018.
Since I come from an academic background, you might expect that this means I consider this project complete and abandon it in favour of some new shiny toy that follows the current trends and fashions to better chase grant money . I am, however, somewhat stubborn and contrarian by nature, or bnlearn would not be what it is today. For many years senior colleagues have told me “time spent writing production-quality software is time wasted”; because software is not a journal publication, it has no impact factor and therefore it is useless. The same happened when I was writing the books I later published with Springer and Chapman & Hall; there were people who could not fathom why I wanted to write a book. “You can write 3-4 papers with that amount of effort!”, and 3-4 publications with impact factor are better than one publication without impact factor, right? I beg to differ. I take pride in my craftsmanship at both writing scientific software and analysing complex data; both can be improved by iteratively revisiting problems to improve over previous solutions. I certainly find engineering good software that other people use as a foundation for their own work more rewarding than publishing a paper in a posh journal knowing that only the three other people working in that particular niche will ever read it. And it is my conviction that statistical methods do not really “exist” unless there is a fast, scalable, well-designed software implementation. Just publishing them does not make them in any way useful, because the time, effort and expertise it takes to implement them puts them out of the reach of most potential users. Would you invest a sizeable amount of time to implement something you are not sure it even works for what you need to do, especially if you do not come from a background with software engineering or computer science skills?
It is with this spirit than I am looking forward to the next 10 years of developing bnlearn; there certainly are enough things I have no idea how to do to keep me occupied for at least that long. A quick look into my private master repository, just out of curiosity, suggests I each of the releases in the last 3 years is larger than the previous one by at least 1000 lines. The grand totals are ≈ 20000 lines of C code and ≈ 19000 lines of R code, with the former increasing much faster than the latter.
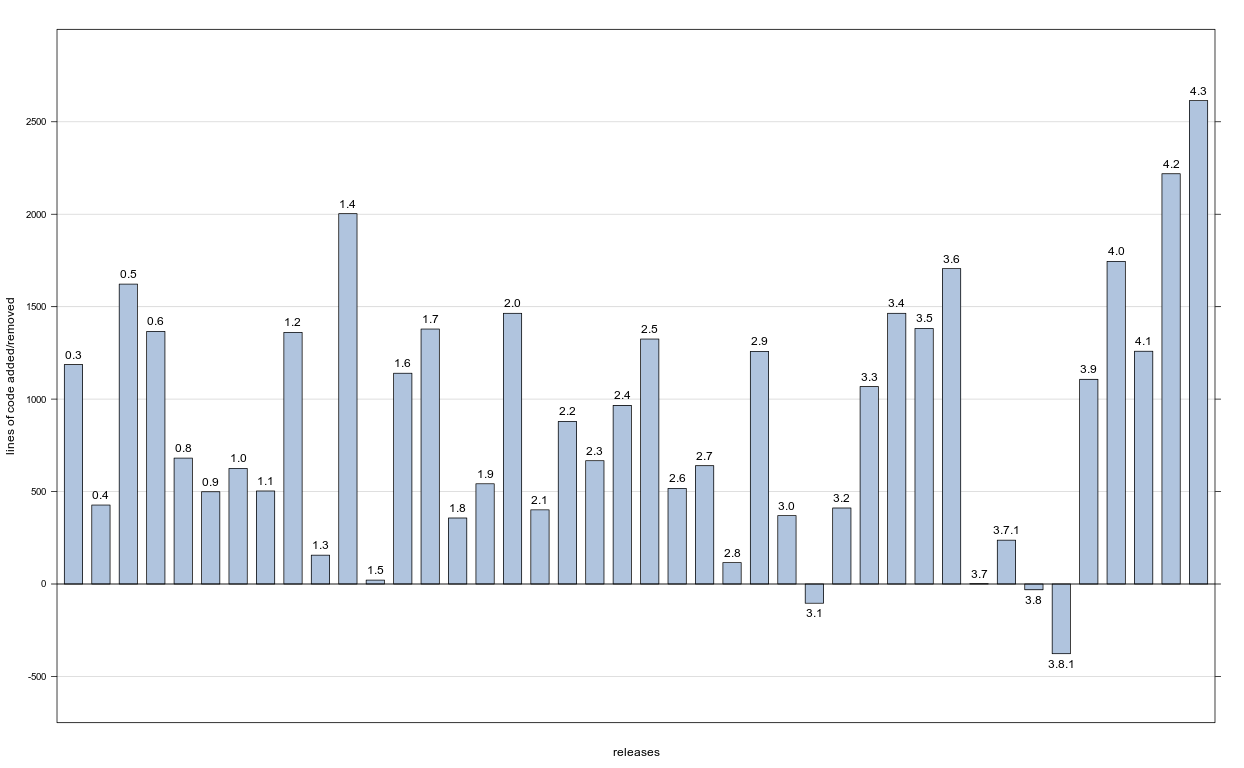
Apparently I have not been slacking off too much!
And with the current rate of requests for new features in bnlearn and new collaborations to tackle tricky data analyses I am not likely to slack off in the future either.
Marco Scutari
Oxford, UK, June 2018

